How Walmart uses LLMs to manage its massive product catalogs

Ever wonder what topics are top of mind for our technologists? As part of a series we’re experimenting with, we’re sharing the trends our teams are observing, their insights and approaches. In this edition, Binwei Yang explores building scalable, effective, and economical large language models that manage hundreds of millions of data points across our enterprise.

Imagine searching for a bright red cocktail dress and ending up with a royal blue maxi dress instead. Frustrating, right? For online retailers, inaccurate and inconsistent product data isn’t just a minor inconvenience—it’s a major issue leading to disappointed customers and operational nightmares.
Our vast catalog contains billions of data points. It’s meant to be the single source of truth, however maintaining it manually would be an unending Herculean effort. That’s where large language models (LLMs) come in. They revolutionize how we manage our product information at scale.
The Power of AI in Product Catalogs
LLMs are AI powerhouses capable of analyzing text and images to extract product attributes like color, size, and material. Unlike traditional methods, they can validate this information at scale, ensuring our catalog becomes a reliable source of truth. The result? A more delightful search experience for our customers and a significant boost to our operational efficiency.
How do we guide LLMs to extract the right information?
LLMs rely on precise prompts to perform well. We create these prompts based on well-defined specifications, guiding the LLM to identify specific attributes. By leveraging product type information and item-specific details, we ensure accurate extraction, allowing customers to find exactly what they’re looking for.
Moreover, we can customize LLMs and make them specific to the task, further enhancing their capabilities in identifying and generating the right outputs.
How do LLMs compare with supervised models?
While supervised models excel in precision, LLMs shine in capturing a wider range of values, offering superior recall when dealing with the diverse product descriptions we encounter. Additionally, a single LLM can handle numerous attributes, streamlining maintenance and monitoring.
LLMs also require less training data, making them more scalable across a vast array of attributes in our catalog. This enables us to build and train them quite quickly.
Our multi-agent approach: Divide and conquer
Our innovative two-step process separates attribute extraction from quality checking, improving accuracy:
- Attribute Extraction: One LLM identifies relevant attributes from product descriptions and images.
- Quality Check (QC): A separate LLM, trained on human-validated data, verifies the accuracy of the extracted attributes.
This multi-agent system acts as a series of specialized experts, allowing for targeted data and optimization. Fine-tuning these experts reduces the footprint of pre-trained general-purpose LLMs by distilling their knowledge to smaller, open-source LLMs. This task-specific model matches the power of pre-trained LLMs while saving inference cost.
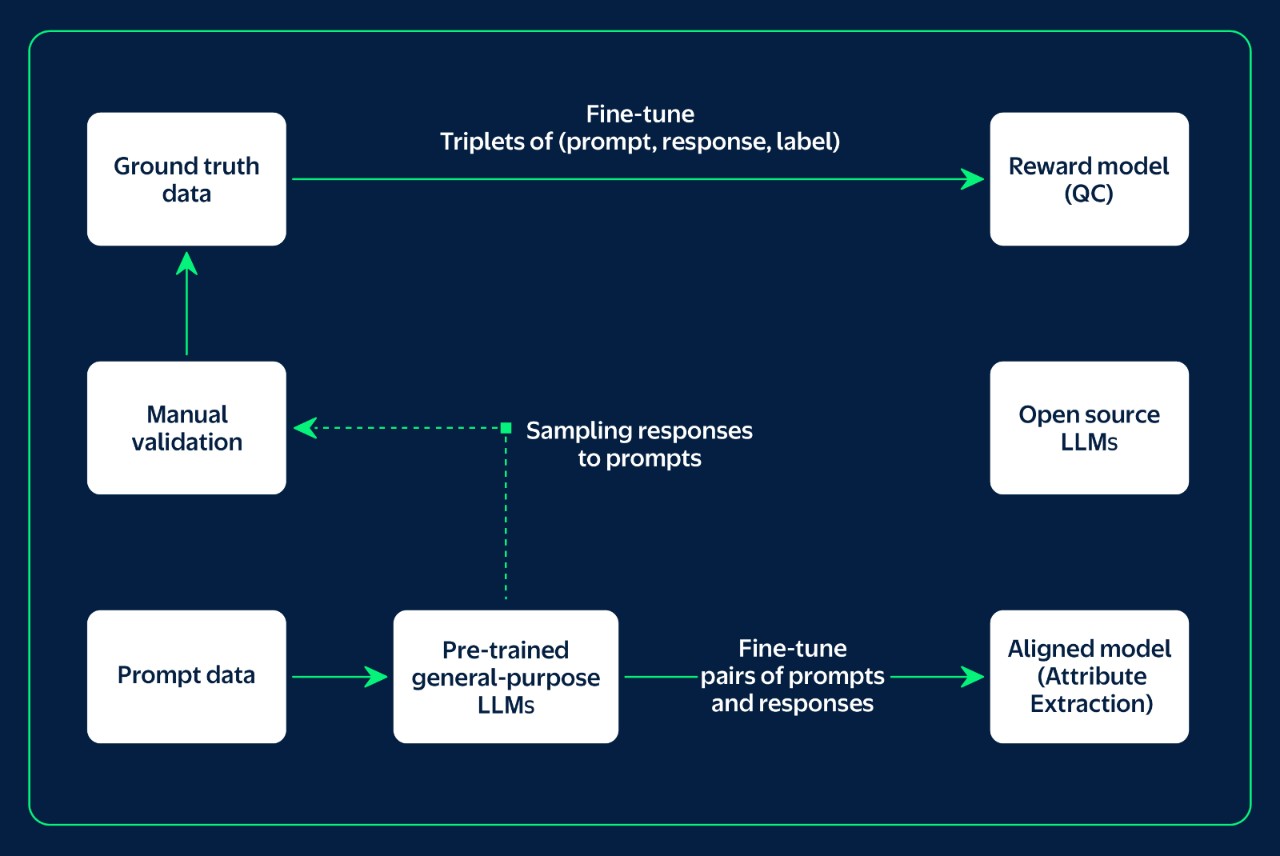
Separate agents for attribute extraction and quality check
The attribute extraction model focuses on providing the values for various attributes. The QC model samples prompts and responses from attribute extraction models and collects human feedback indicating whether the attribute value is correct, with a goal of creating a reward model that closely approximates how human specialists evaluate attributes. Think of it this way: the first LLM is a skilled writer creating a description, and the second LLM is a meticulous editor, ensuring all facts are correct.
The performance gap: Why we need quality checks
Early LLM models struggled with accurately extracting product attributes, often making mistakes. Models have improved significantly but still have limitations. For attributes where LLM accuracy is above a certain threshold (typically 90-95+% depending on the attribute), we can confidently ingest the extracted values into our catalog. But what about attributes where accuracy falls below the threshold?
This is where the quality check model comes in. By training the QC model on a larger and more diverse dataset, including various product types and attributes, we enable it to make more accurate predictions and generalize better to new, unseen data. This approach helps mitigate the risk of overfitting, where the model performs well on training data but poorly on new data.
A well-trained QC model reduces the reliance on manual validation of GenAI outputs, freeing up human quality assurance specialists to focus on more complex tasks. This automation improves operational efficiency.
Building a robust quality check model
One crucial lesson is that high-quality, manually validated data is paramount. The role of human insights, which provide the ground truth labels for fine-tuning our models, cannot be overstated. Each attribute has a detailed specification that human specialists follow. Attributes could be defined with closed list, use a normalized form of unit of measurement, have variations with equivalent meaning, or several other rules that leave room for interpretation. Although human judgments are inherently subjective, they go beyond simple cross-checking to establish the ground truth of whether an attribute value is correct, wrong, or somewhere in between.
Within our team, we use a triplet of input data in the form of item information, attribute value, human label, to fine-tune our specialized QC model. Both the text description and the image are analyzed to fully extract the item's attributes. When we ask for human validation, we recognize that for each item there is only a single truth, captured in one set of attributes—regardless of the information source.
During validation, humans will mark the specific source—usually text or image—for each attribute, creating a nuanced annotation process. This approach ensures we can trace the origin of each validated attribute while maintaining a unified view of the item's characteristics.
Our future fine-tuning strategy for the QC model will depend on several key considerations:
- For visually dependent attributes, the item's image becomes crucial.
- When higher validation precision is needed, we may leverage both text and image inputs.
- If fast inference is a priority, we might rely solely on item text.
This flexible approach allows us to optimize our model's performance based on the specific requirements of different product attributes.
Finally, the benchmark datasets are versioned. We make sure there is no overlapping between the training and benchmark datasets. To ensure comprehensive and robust quality control, we've developed a nuanced approach to benchmark dataset construction. This includes strategically differentiating our datasets to support rigorous validation across two critical dimensions:
- LLM-Specific Benchmark Datasets: These datasets are tailored to evaluate the performance of specific LLMs used in attribute extraction. By creating LLM-specific benchmarks, we can assess the unique strengths and limitations of individual attribute extraction models.
- LLM-Agnostic Benchmark Datasets: These datasets are designed to be model-independent, focusing on the broader challenge of attribute extraction across different content providers.
This dual-benchmark approach addresses the complexity of our multi-source, multi-model attribute extraction process, and enables us to continue to work with multiple content providers and employ various attribute extraction LLMs.
The Power of Multi-Task Fine-Tuning
While fine-tuning LLMs on domain-specific data is crucial for optimal performance, there's risk of the LLM forgetting previously learned general language skills. We can address this by striking a balance, ensuring that the LLM can understand both the specifics of our catalog – think “men’s athletic shoes,” and broader language contexts, such as understanding color variations.
In practical implementation, we observed the benefits of fine-tuning LLMs on multiple related tasks simultaneously. Multitask fine-tuning allows the model to share knowledge across tasks, potentially leading to improved overall performance. For example:
- We incorporate high-precision predictions from existing computer vision models as synthetic data.
- We leverage LLMs with reasoning capabilities to generate rationales for human-validated labels. This method is inspired by the Self-Taught Reasoner technique.
In multitask fine-tuning, each task could be prompted to contextualize the response. For example, instead of providing a simple prompt like “validate the attributes based on the product name or product type or image caption,” we can add “in addition, you are able to think step by step and explain each validation result.”
Instead of multiple variants of LLMs, one LLM could understand different instructions. This approach not only improves accuracy but also enhances the models’ ability to handle diverse product descriptions and attributes.
The rise of generalist LLMs in e-commerce
Recent research reinforces the benefits of our multi-task approach, highlighting the advantages of generalist LLMs compared to state-of-the-art task-specific LLMs in e-commerce applications, to “bridge the gap and develop e-commerce foundation models with real-world utilities for a large variety of e-commerce applications.” A generalist LLM is fine-tuned on multiple tasks including attribute value extraction. This aligns with our goal of creating versatile models that can handle a wide range of e-commerce tasks while maintaining high performance.
Continuously refining our LLM approach has been an iterative journey
Developing a robust LLM-based solution is an iterative process. We continuously refine our models by incorporating new data sources, techniques, and insights. This ensures that our system remains effective as the catalog evolves and LLMs improve.
Knowledge Distillation
Knowledge distillation (KD) is like teaching a smaller, less experienced student how to solve problems by learning from a more knowledgeable teacher. Think of it as a wise, experienced chef—the teacher model—helping a junior apprentice—the student model—learn complex cooking techniques. KD effectively enhances LM’s performance through:
- Initial fine-tuning of both large and small LMs;
- Identification of attribute-level performance gaps;
- Generation of supplementary training data from larger models;
- Targeted attribute-specific improvements.
In our attribute extraction process, we carefully select attributes where this "knowledge transfer" can be most effective. We look for specific attributes where:
- The teacher model shows significantly better performance than the student model;
- The teacher model achieves high precision;
- The student model struggles with recall.
To ensure we're truly improving the student model, we have a simple rule: we only choose attributes where the student isn't already doing a great job. If the student model is already performing well across accuracy, precision, and recall, we leave that attribute alone. This approach helps us focus on areas with the most room for improvement.
The magic of knowledge distillation is that it allows us to create a smaller, faster model that can perform almost as well as the larger, more complex model. It's like teaching a young chef to cook complex dishes using fewer ingredients and simpler techniques, without losing the essence of the original recipe.
Overcoming technical challenges
LLMs present significant computational challenges, which we address through a holistic optimization strategy. Our approach leverages four key techniques that work synergistically to dramatically reduce memory requirements and enable more efficient model training:
- Low-Rank Adaptation (LoRA): By training only a small set of parameters, we reduce gradient complexity and minimize memory overhead. This technique directly supports our goal of using smaller language models more effectively.
- Quantization: Utilize lower-precision numerical representations for storing weights (trained and frozen) to reduce memory requirements, though it might increase training time.
- Gradient Checkpointing: Selectively store and recompute gradients during training to reduce memory usage.
- Flash Attention: Employ memory-efficient attention mechanisms within transformers to decrease memory usage and accelerate training.
These optimization techniques are not standalone solutions, but a carefully orchestrated approach that enables our core strategy: using smaller language models while maintaining high performance. Crucially, these techniques make it possible to limit computation to a single GPU.
Our deliberate choice to restrict training to a single epoch is equally strategic. By limiting training duration, we aim to preserve the foundational knowledge of the base LLM while making fine-tuning more efficient. This approach ensures that we don't overwrite the model's pre-trained general knowledge, instead making targeted, precise improvements for specific tasks.
The result is a pragmatic methodology that democratizes AI development. By focusing on efficiency alongside performance, we’re working to create a system that’s not only accurate but also practical and cost-effective at scale. We're proving that intelligent model optimization can democratize access to advanced AI technologies, making sophisticated machine learning more accessible to researchers and developers with limited resources.
The results and future outlook
By leveraging this multi-agent, multi-task LLM approach, we’ve significantly reduced inaccuracies in our catalog. This translates to a more delightful search experience for our customers, who can now find products with greater ease. Additionally, the automation frees up human resources for more complex tasks.
As LLMs continue to advance, we’re excited about their potential to further revolutionize our operations and provide an even better experience for our customers. The future of retail is here, and it’s powered by AI.
Explore more stories



 LinkedIn
LinkedIn
 Twitter
Twitter

