Driving faster experimentation through interleaving in Walmart Search

Ever wonder what topics are top of mind for our technologists? Garima Choudhary explores how interleaving, a standard approach to testing, accelerates search innovation, driving faster experimentation, smarter insights, and more relevant results for customers. With special thanks to Rudrani Ghosh, Girish Thiruvenkadam and Shipra Agarwal for their valuable input, feedback and review.

When a customer searches for a product on Walmart.com or in the app, they expect the best results instantaneously. Whether they are looking for a specific brand of cereal or comparing products, the goal is the same: make it easy to find what they want, when they want it.
On the backend of every search, our search system is constantly learning and evolving. With millions of items and countless search queries daily, surfacing the most relevant results is not just important; it’s the difference between a satisfied customer and a lost sale.
Improving search at Walmart means constantly testing new ideas: better ranking models, smarter query interpretation, or algorithms that understand product relationships in new ways. While testing ideas is essential, traditional A/B testing takes time. It requires large amounts of traffic, runs for weeks, and can only test one change at a time. That means great ideas are often backlogged, slowing innovation.
At our scale, that delay adds up. We needed a quicker, more efficient way to experiment without sacrificing accuracy or customer experience. Enter interleaving: a standard approach to testing that allows us to compare search algorithms side by side, learn from real customer interactions, and improve relevance faster than ever before.
What is interleaving?
At its core, interleaving is a faster, fairer way to compare search algorithms. Instead of showing one model’s results to one group of users and a different model’s results to another group, as A/B testing does, interleaving blends the outputs of both models into a single, shared search results page. By testing competing algorithms simultaneously with the same users, we can dramatically accelerate our experimentation cycle.
There are three primary interleaving methods Balance Interleaving, Team Draft Interleaving, and Probabilistic Interleaving.
Balanced Interleaving
Balanced Interleaving (BI) fairly combines two ranked lists by alternating their top results, ensuring both models contribute equally to the final output.
In the example below, rank denotes the position of items. BI merges the lists from algorithms A and B by taking turns selecting the highest-ranked unused item from each list. A coin toss decides which algorithm picks first. If A wins, A adds its top remaining item to the merged list, then B adds its top remaining item, and so on until the list reaches the desired length.

However, BI can introduce bias when both algorithms return the same items in different orders. For example, if item Z is ranked first by A but last by B, the alternating pattern may end up favoring B—showing how BI can skew results even when the two lists contain the same items.
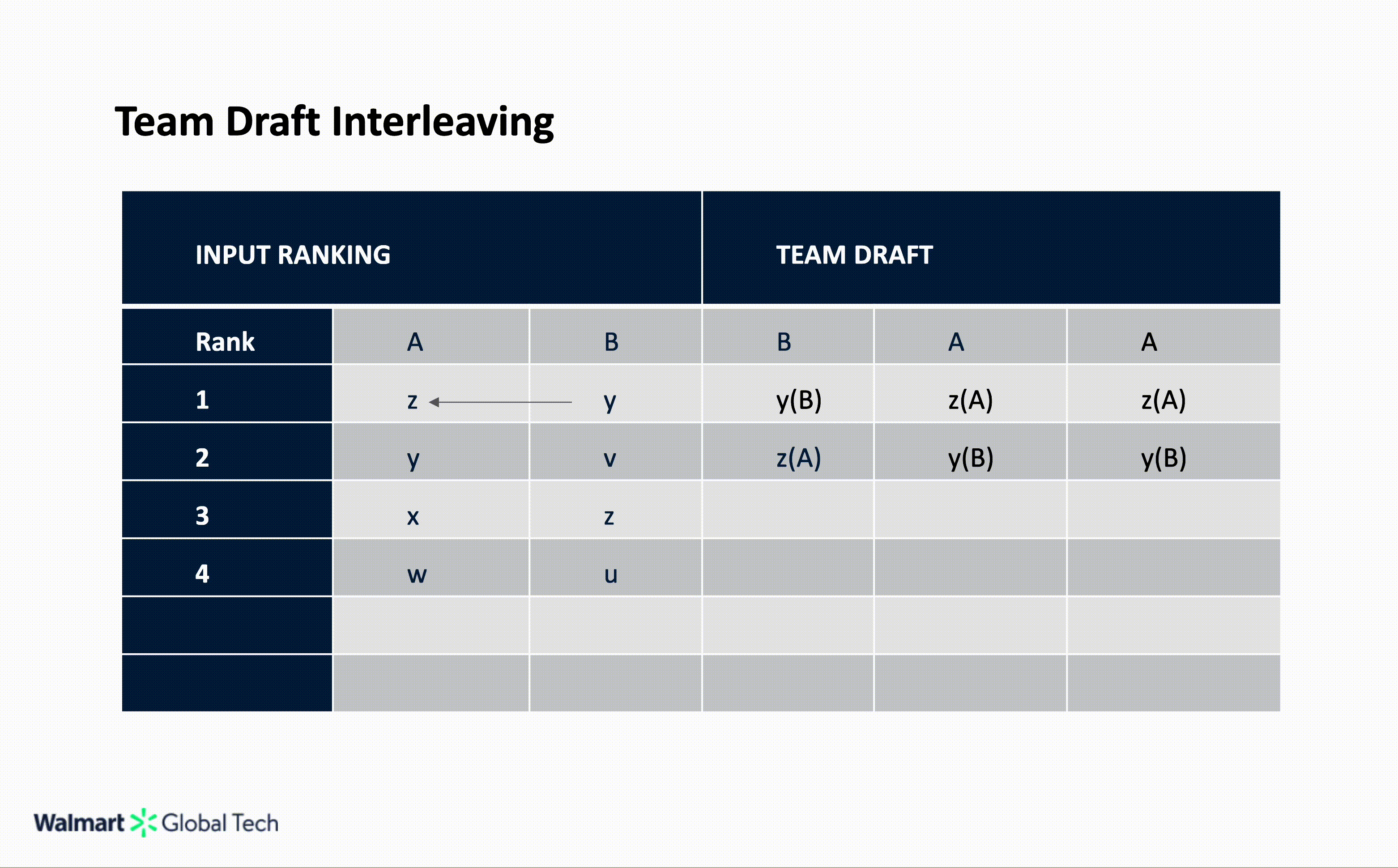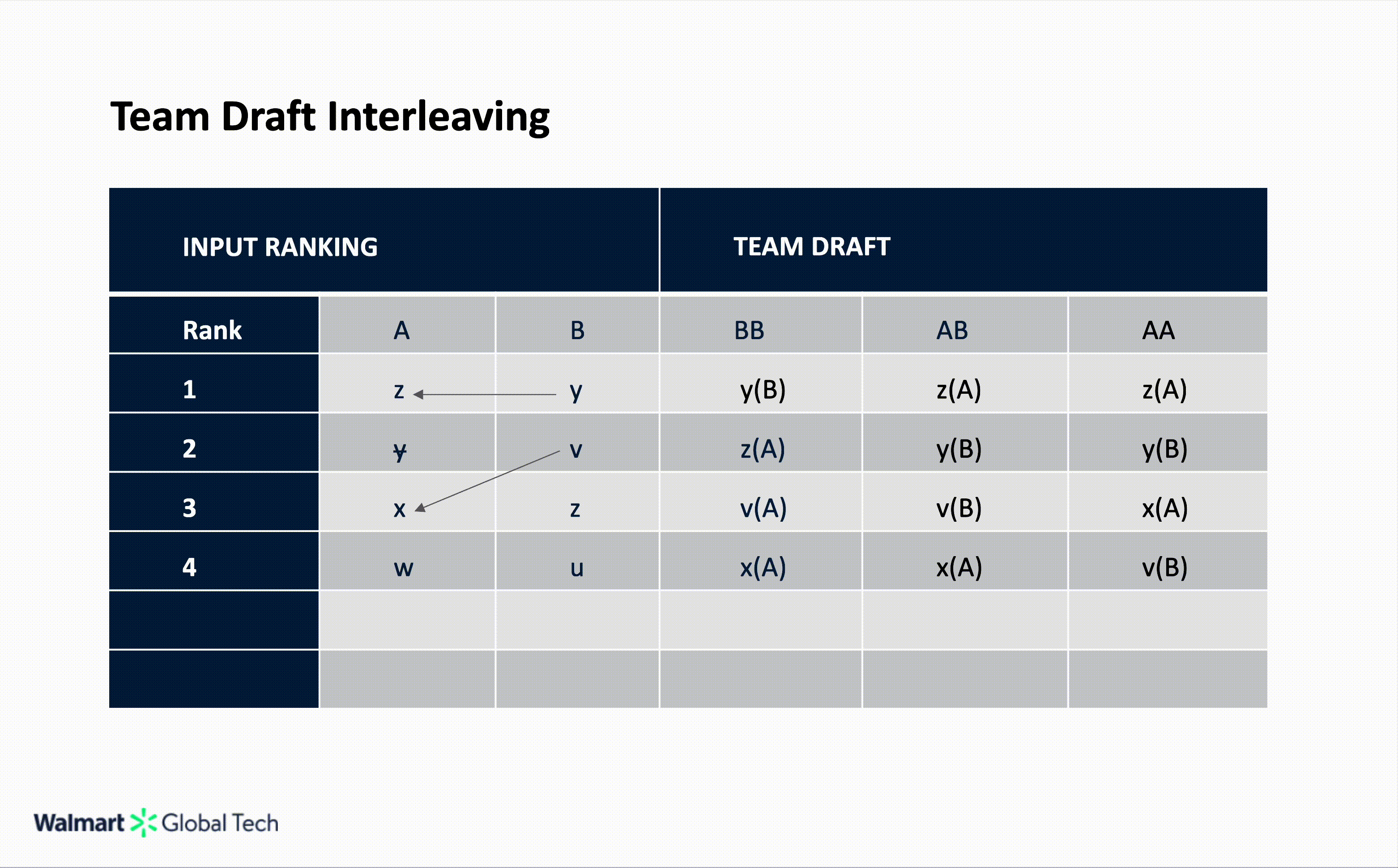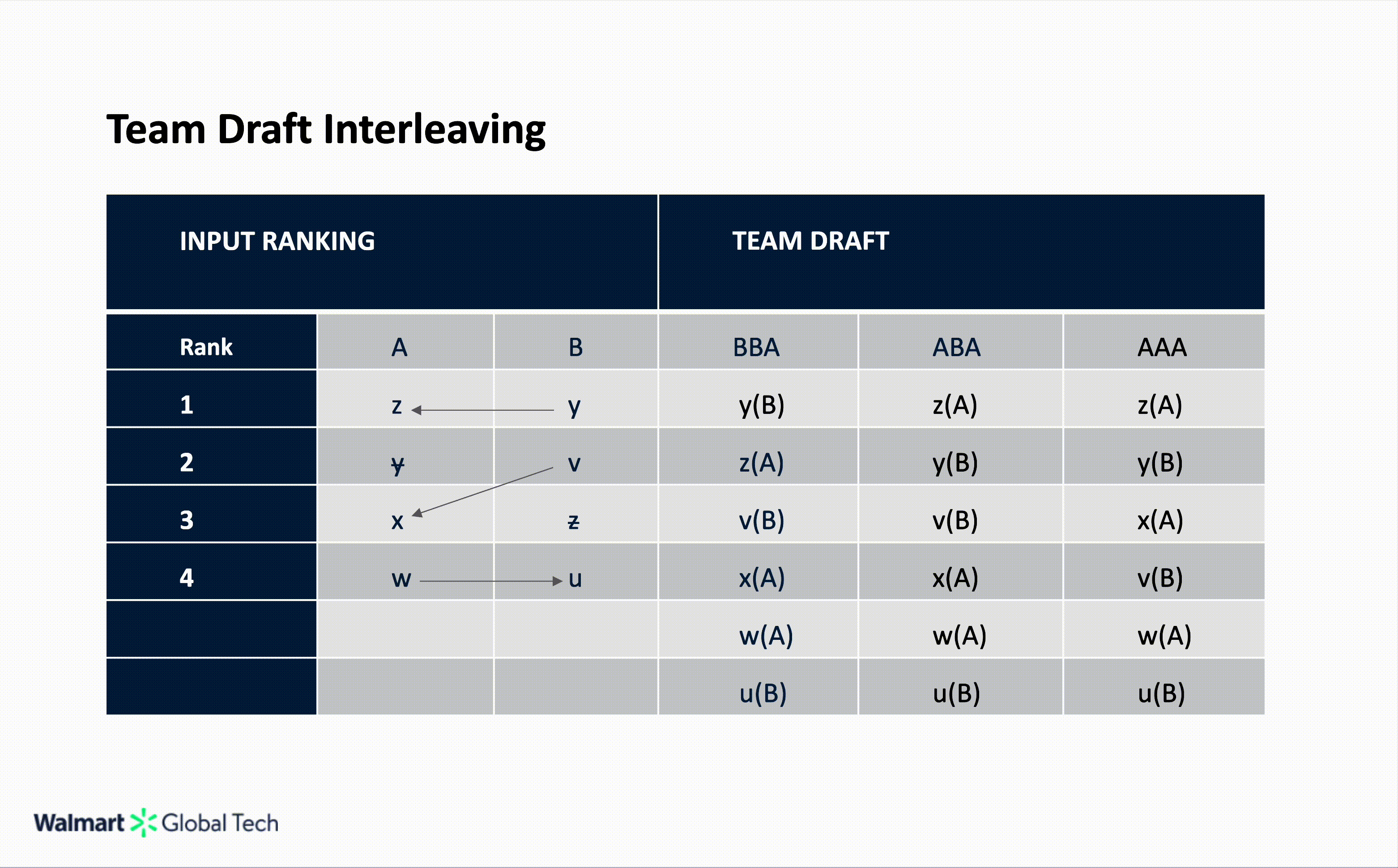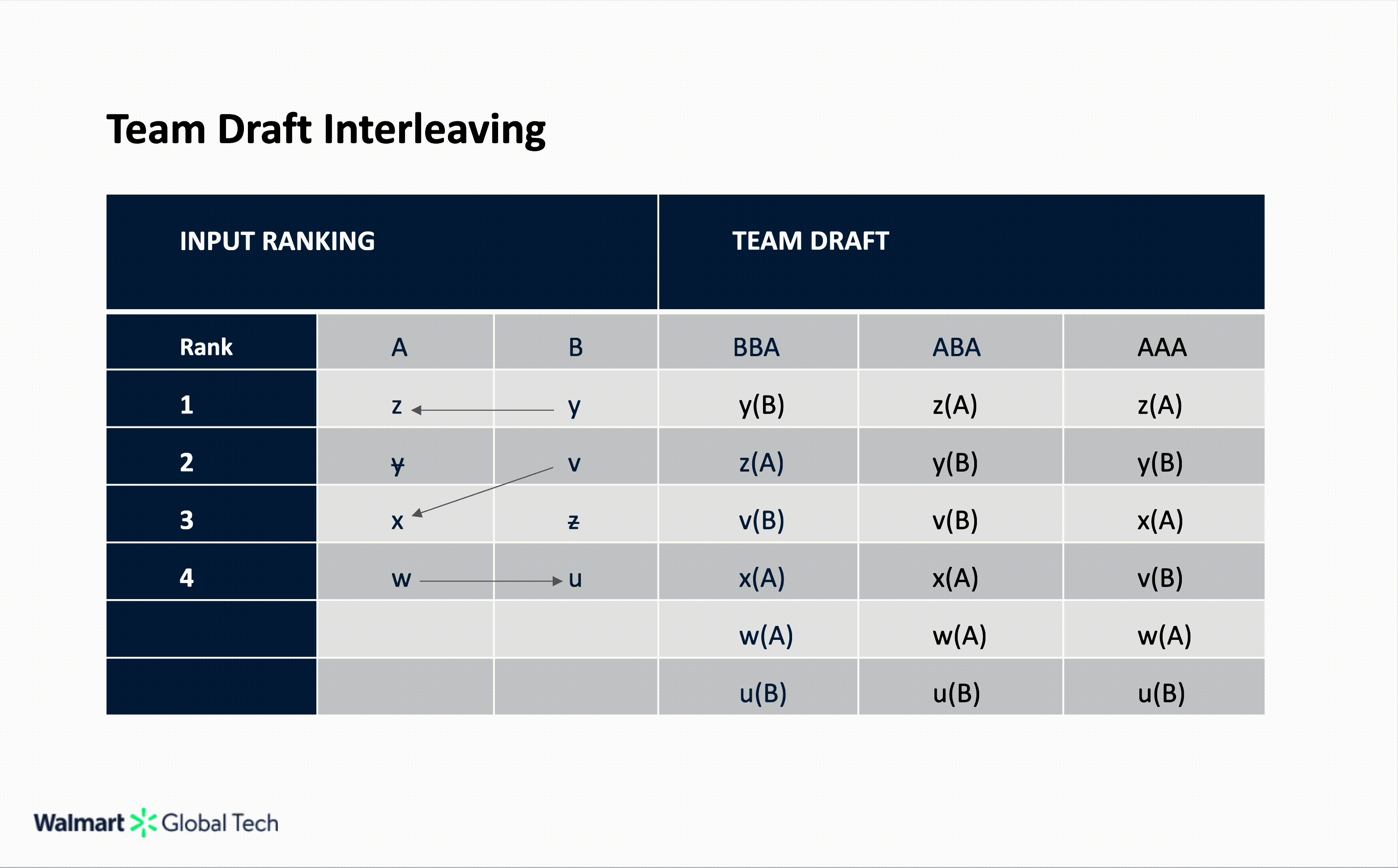
Team Draft Interleaving
Team Draft Interleaving (TDI) alternates selections in a draft-like fashion to ensure each list contributes equally to the final merged list. In TDI, the merged list is not unique; different coin-toss outcomes lead to different merge lists. Each round begins with a coin toss.
If the coin lands on heads, ranker A picks first; if it lands on tails, ranker B starts. The rankers then alternate, taking turns selecting the highest-ranked item that hasn’t yet been added to the merged list. When possible, each round produces two picks, one from each ranker, before the next round begins with another coin toss. This continues until the merged list reaches the desired length.
Probabilistic Interleaving
Probabilistic Interleaving takes it a step further by sampling results based on how confidently each algorithm ranks an item, rather than simply alternating between them and is ideal for more nuanced evaluations.
In the example below, we first generate scores for each item using an exponential decay function based on its rank. These scores are then normalized so they sum to one, creating a probability distribution for each algorithm. Those probabilities determine the likelihood that an item will be selected during the merging process. Because selection is random, multiple valid merged lists are possible.

Since the merged list is created through sampling, the outcome can vary each time. But by running the simulation many times (e.g., 10,000 iterations), we can estimate the probability that each item is selected by Ranker A or Ranker B.

Attribution Methods
Understanding interleaving experiments isn’t just about which items customers click; it's about correctly attributing those interactions to the algorithm that most influenced them. To do this, we’ve developed multiple attribution methods to evaluate conversion-focused business metrics, such as clicks and add-to-cart (ATC) actions, to determine whether Algorithm A or Algorithm B performs better.
We use two primary attribution methods:
- Method 1: Credit is assigned to both algorithms if the clicked item appears in both lists, regardless of its position.
- Method 2: Credit is assigned only to the algorithm where the clicked item ranks higher. This method also incorporates the rank difference to more accurately reflect the impact of item positioning.
We then aggregate these metrics and assess the statistical significance of the differences in engagement (e.g., clicks, ATCs) between the Algorithm A and B groups using hypothesis testing. This ensures that observed variations are meaningful and not due to random chance.
Each interleaving approach offers a different balance between simplicity, fairness, and analytical depth, and can be calibrated to fit the goals of each experiment, from early-stage comparisons to fine-tuning top-performing models.
Where it differs from A/B testing
In interleaving, every customer interaction teaches us something. Each click or add-to-cart is attributed to the algorithm that surfaced the item, building a real-time picture of which model performs better, without waiting weeks for separate test results.
Traditional A/B testing, by contrast, relies on distinct user groups, which can introduce differences like time of day, location, or customer intent, that influence outcomes. Interleaving removes that variability by showing both algorithms’ results to the same users in the same context.
It also means new ideas can be tested and refined in days rather than weeks. Promising models move forward to larger scale A/B testing, while weaker ones are filtered out early without disrupting the customer experience.
This enables our teams to innovate more rapidly and bring improved search relevance to customers faster than ever before.
Interleaving’s impact
Interleaving has reshaped how we evaluate and evolve our search experience. It enables teams to experiment continuously, gather insights in real time, and apply data-driven improvements at a pace that matches the speed of our customers’ needs. The result is a faster, more flexible approach to innovation that keeps search results fresh, relevant, and responsive.
Several factors make interleaving especially effective:
- Simultaneous evaluation: Interleaving mixes results from two algorithms into a single ranked list shown to the same user during one session. This allows direct comparison in real time; no separate test cycles required.
- Faster feedback: Each click, view, or add-to-cart provides immediate insight into which algorithm performs better, dramatically shortening the feedback loop.
- Higher sensitivity: Because it measures performance at the individual item level, interleaving can detect even small differences in algorithm quality.
- Lower variance: Since the same user sees results from both algorithms, factors like user preferences and context are controlled for reducing noise in the data.
- Efficient use of traffic: Every customer interaction contributes to evaluating both algorithms, meaning fewer users are needed to achieve statistically confident results.
Still, like any experimentation method, interleaving works best when used in the right context. It’s ideal for fine-tuning similar algorithms or validating small ranking improvements, but it’s not a replacement for A/B testing in every case.
- Complex implementation: Interleaving requires sophisticated technical infrastructure to merge and attribute results accurately. The analysis can also be more difficult to communicate to non-technical audiences compared with traditional A/B test outcomes.
- Limited use cases: Because it compares similar ranking algorithms, interleaving isn’t suitable for testing major changes such as new page layouts, UI designs, or fundamentally different search strategies.
- Traffic requirements: While more efficient than A/B testing, interleaving still depends on sufficient user interactions to confidently detect performance differences, especially when algorithms behave similarly.
For these reasons, interleaving and A/B testing are often used together. Interleaving accelerates early learning, helping teams identify and refine promising models quickly. A/B testing then validates those improvements at scale, ensuring that what works in early experiments also performs reliably across millions of customer searches.
Ultimately, the goal isn’t just faster testing, it’s making better decisions that improve the customer experience while maintaining result quality. The future of search lies not only in better algorithms, but in better ways to test them.
Explore more stories




 LinkedIn
LinkedIn
 Twitter
Twitter

